Optimizing Gaussian blurs on a mobile GPU

With the launch of iOS 7, and its use of blurs throughout the interface, there's been a lot of interest in fast ways of blurring content. GPUImage has had a reasonably performant, but somewhat limited Gaussian blur implementation for a while, but I've not been happy with it. I've completely rewritten this Gaussian blur, and it now supports arbitrary blur radii while still being tuned for the iOS GPUs. At higher blur radii, I'm slower than Core Image, though, and I don't quite understand why.
How a Gaussian blur works
A Gaussian blur works by sampling the color values of pixels in a radius around a central pixel, then applying a weight to each of these colors based on a Gaussian distribution function:
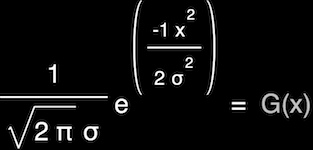
As the radius of a Gaussian blur grows, it quickly becomes an extremely expensive operation. For a Gaussian blur that acts over an area 9 pixels in diameter, you're looking at 81 pixels that need to be read, weighted, and summed for every single pixel in your input image. This grows as a square of the strength of your blur, so you can see how this can add up to a lot of computation per blurred image.
Thankfully, GPUs are built to do parallel operations like this. With the proper use of a fragment shader, these blurs can be done much faster than on the CPU, but even there optimizations are needed to make these fast.
Reducing the number of texture reads
As mentioned, a blur like this can performed using a fragment shader, a small C-like program that is used by the GPU to perform operations on every fragment (pixel) of an input texture (image). Optimizing these shaders can be more of an art than a science sometimes, but there are some general rules to follow. One of these rules is that you should minimize the number of pixels you read within a given fragment shader, and a closely related one is that you should minimize the number of calculations performed within one.
To this end, there are two significant optimizations that can be made to a Gaussian blur on the GPU. The first relies on the fact that a Gaussian blur is a separable operation. That is, rather than blurring in both X and Y at once, you can first blur in one direction, and then the other. This means that for our example of a 9-pixel-diameter blur, you go from 81 operations per pixel to two passes of 9 operations (for a total of 18).
The second large optimization, as described by Daniel Rákos in his great article on the subject, is to use hardware interpolation on the GPU to nearly halve the number of operations. When you have linear interpolation enabled for a texture in OpenGL, if you read anywhere between two pixels, you get back a weighted average of those two values. You get this interpolation for free, and it turns out that if you read from just the right position between the pixels for a Gaussian blur and adjust the weights to match, you get the exact same results as if you had read and weighted each of the pixels individually.
To convince myself of this, I took Daniel's weighting equations and compared them to standard Gaussian weights. I did so by blurring a one-pixel wide value of 1.0 using a blur with a 9 pixel area (a 4 pixel radius) and a sigma (blur strength) of 1.83. The results for the standard Gaussian and the optimized one were identical:
| Pixel Position | Standard Gaussian Result | Optimized Gaussian Result |
| 0 | 0.0204001988 | 0.0204001988 |
| 1 | 0.0577929595 | 0.0577929595 |
| 2 | 0.1215916882 | 0.1215916882 |
| 3 | 0.1899858519 | 0.1899858519 |
| 4 | 0.2204586031 | 0.2204586031 |
| 5 | 0.1899858519 | 0.1899858519 |
| 6 | 0.1215916882 | 0.1215916882 |
| 7 | 0.0577929595 | 0.0577929595 |
| 8 | 0.0204001988 | 0.0204001988 |
This means that you can do a blur over a 9 pixel area using only 5 texture reads. Combining these optimizations, you go from 81 pixel reads for our 9-pixel-area blur to a total of 10.
I had been experimenting with this in GPUImage within the GPUImageFastBlurFilter, but this is now at the core of my mainline Gaussian blur filter (and thus I've removed the GPUImageFastBlurFilter from the framework).
Optimizing a shader for a mobile GPU
Once the larger optimizations are out of the way, there are other things that can be done to speed up fragment shaders. The first such optimization is making sure that the Gaussian weights are calculated ahead of time and baked into the shader. There's no need to waste precious GPU computational cycles applying the above equation to every pixel.
You'll also want to reduce dependent texture reads within your fragment shader when tuning for iOS devices. Dependent texture reads are ones where the location you're reading from is calculated within the fragment shader, instead of being passed in from the vertex shader. These dependent texture reads are much more expensive for the GPUs used in current iOS devices, because they work against caching and other capabilities of these GPUs. To prevent a dependent texture read, you'll want to calculate the positions for each texture read in your vertex shader and pass the results to the fragment shader via varyings (variables that are interpolated across each fragment in a drawn triangle).
The thing about both of these optimizations, as well as the optimized Gaussian weighting described above, is that fragment shaders using them must be individually crafted for each sampled blur radius and value of sigma that you use in the Gaussian distribution function. Calculating and writing shaders by hand for every possible radius / sigma combination is impractical at best. This is why my older Gaussian blur in GPUImage would show artifacts, because it was tuned for only one sampling radius and if you pushed it past that by increasing the per-pixel sampling distance it would skip pixels and start to get blocky.
Therefore, I've written methods within GPUImage that generate vertex and fragment shaders on the fly based on these parameters. Sample vertex and fragment shaders created by these methods look like the following (a radius-4 sampling area with a sigma of 2):
Vertex shader:
attribute vec4 position;
attribute vec4 inputTextureCoordinate;
uniform float texelWidthOffset;
uniform float texelHeightOffset;
varying vec2 blurCoordinates[5];
void main()
{
gl_Position = position;
vec2 singleStepOffset = vec2(texelWidthOffset, texelHeightOffset);
blurCoordinates[0] = inputTextureCoordinate.xy;
blurCoordinates[1] = inputTextureCoordinate.xy + singleStepOffset * 1.407333;
blurCoordinates[2] = inputTextureCoordinate.xy - singleStepOffset * 1.407333;
blurCoordinates[3] = inputTextureCoordinate.xy + singleStepOffset * 3.294215;
blurCoordinates[4] = inputTextureCoordinate.xy - singleStepOffset * 3.294215;
}
Fragment shader:
uniform sampler2D inputImageTexture;
uniform highp float texelWidthOffset;
uniform highp float texelHeightOffset;
varying highp vec2 blurCoordinates[5];
void main()
{
lowp vec4 sum = vec4(0.0);
sum += texture2D(inputImageTexture, blurCoordinates[0]) * 0.204164;
sum += texture2D(inputImageTexture, blurCoordinates[1]) * 0.304005;
sum += texture2D(inputImageTexture, blurCoordinates[2]) * 0.304005;
sum += texture2D(inputImageTexture, blurCoordinates[3]) * 0.093913;
sum += texture2D(inputImageTexture, blurCoordinates[4]) * 0.093913;
gl_FragColor = sum;
}
For those unfamiliar with shaders, the vertex shader is run once per vertex in your geometry (I have four vertices used to draw the two triangles that make up the rectangular image being processed) and the fragment shader once per fragment (roughly, pixel). Uniforms are variables that are passed into the shader program (the combination of the vertex and fragment shader) from your code, and varyings are variables that are passed between the vertex and fragment shaders. Because my OpenGL ES coordinate system is normalized to 0.0 - 1.0, I need to pass in the fraction of the width and height of an image that a pixel accounts for (texelWidthOffset, texelHeightOffset) so that I can calculate the spacing between pixels in the source image. The optimized offsets to read color values from are calculated in the vertex shader and passed into the fragment shader, which reads from these locations and applies the optimized Gaussian weights to arrive at the final output color.
The inner portions involving blurCoordinates[x] of both shaders are what I generate in my methods, and the resulting shader program is compiled and linked as needed at runtime. You will see a hitch when switching between blur levels as a result, but the overall performance win is more than worth it.
There is a limit to one portion of the shader auto-generation, and that's how many texture read offsets that can be calculated in the vertex shader. The iOS GPUs have a hard limit for the number of varying components that can be passed between vertex and fragment shaders (32), which means that I can only pass about 8 elements in the blurCoordinates array. At large enough blur radii, the rest have to be calculated in the fragment shader, which slows things down but is unavoidable due to hardware constraints.
I found that Core Image used the sigma parameter from the Gaussian distribution as its inputRadius parameter for CIGaussianBlur, so I've maintained that convention with the blurRadiusInPixels property of the GPUImageGaussianBlurFilter. That doesn't tell you how many pixels you need to sample out from the central pixel, though, since a Gaussian distribution could theoretically extend to infinity. What I've done is limit the sampling radius to the point at which the Gaussian contribution from a pixel at that radius becomes negligible (2 / 256ths or so). I then normalize my Gaussian weights to prevent darkening of the image when truncating the sampling area like this.
One problem I've found with this is that it appears there's a bug in iOS 6 where sigma values of 25 and above lead to the generation of shaders that crash an OpenGL ES context (the screen goes black and nothing will be rendered from any shader on that context again). This is not the case on iOS 7, however, but is something to watch out for.
I now also use a similar process to that described above, without the Gaussian weights, for generating a variable-radius box blur in my GPUImageBoxBlurFilter, and I'll be extending the remaining blur filters to use this as well.
Benchmarks
I benchmarked the performance of this new blur implementation at a series of pixel sampling radii when operating against 720p video. This should provide a good test, since it's a fairly large image size, and I have a fast path for obtaining video so overhead from everything surrounding the blur operation should be minimal. I'm using pixel sampling radii here, so that assumptions about sigma and where to cut off sampling for a given blur size don't come into play. These are the average times (in milliseconds) that it took to process a single frame of 720p image data and display it to the screen using these new optimized Gaussian blurs:
| Pixel Sampling Radius | iPhone 4 | iPhone 4S | iPad 3 | iPhone 5 | iPhone 5S |
| 4 | 43 | 5 | 5 | 4 | 1 |
| 8 | 82 | 8 | 8 | 5 | 1 |
| 10 | 147 | 8 | 9 | 5 | 1 |
| 12 | 189 | 25 | 11 | 6 | 2 |
| 14 | 220 | 32 | 12 | 8 | 1 |
| 16 | 278 | 40 | 15 | 9 | 1 |
| 18 | 318 | 45 | 17 | 10 | 1 |
| 20 | 347 | 54 | 18 | 11 | 2 |
| 22 | 394 | 65 | 20 | 12 | 1 |
| 24 | 451 | 76 | 24 | 13 | 2 |
| 26 | 498 | 89 | 29 | 25 | 2 |
| 28 | 558 | 96 | 30 | 27 | 2 |
| 30 | 607 | 103 | 34 | 32 | 2 |
| 32 | 640 | 108 | 36 | 36 | 2 |
| 34 | 722 | 120 | 38 | 41 | 2 |
| 36 | 766 | 130 | 39 | 49 | 3 |
| 38 | 843 | 136 | 42 | 55 | 3 |
| 40 | 873 | 145 | 51 | 55 | 3 |
The iPhone 4 falls to 23 FPS for processing the 720p feed at even the lowest blur radii, the iPhone 4S hits 30 FPS (33 ms / frame) at a sampling radius of 14, the iPad 3 at radius 28, the iPhone 5 at radius 30, and nothing's stopping the iPhone 5S.
I was surprised at how linear the slowdown was in response to increasing the sampled area size for the blur, because I've seen a lot of nonlinear behavior with shaders of increasing complexity. This also revealed very interesting differences in device performance between the various generations of iOS hardware. The iPhone 4 clearly lags behind all others in performance, as there was a giant leap between that and the GPU in the iPhone 4S. Also worth noting is the fact that nothing even came close to slowing down the iPhone 5S GPU. That GPU is a break from the others, with some operations on it being 10-100 times faster than the one in the iPhone 5. It's a real monster when compared to other mobile GPUs.
One caveat to the above is that the iPhone 4 in my tests was running iOS 5, and the 4S and iPad 3 running iOS 6. With every major version of iOS, Apple has increased OpenGL ES performance, so these frame times might be a little lower on iOS 7, although probably not dramatically so.
I've used Core Image as my basis for comparison when it comes to the resulting image after the blur is applied, and I come within 1/256th of their color values in my test cases at similar blur sigma values. As mentioned above, I have to cut off the blur sampling at some point, so I believe this accounts for the slight difference between Core Image's results and mine. It's therefore useful to compare performance between my GPUImageGaussianBlurFilter and Core Image's CIGaussianBlur. The following are frame times for processing a 720p frame using GPUImage and Core Image on an iPhone 4S running iOS 6:
| Sigma | GPUImage | Core Image |
| 2 | 5 | 48 |
| 4 | 18 | 48 |
| 6 | 39 | 49 |
| 8 | 49 | 49 |
| 10 | 67 | 55 |
| 12 | 80 | 56 |
| 14 | 93 | 56 |
| 16 | 101 | 57 |
I have to admit, I was shocked by these results. Core Image is somehow able to maintain near constant-time performance, despite increasing sample radii for a blur area. I repeated this benchmark on an iPhone 5 running iOS 7:
| Sigma | GPUImage | Core Image |
| 4 | 5 | 6 |
| 10 | 11 | 8 |
| 18 | 16 | 8 |
| 24 | 55 | 9 |
and see a similar plateau for the frame processing times of Core Image at high blur radii. Once you get beyond a certain blur sigma, Core Image is clearly faster than my blur filter in every case.
Unless I've screwed up the benchmarks, it's clear they're using a different process for generating their Gaussian than strictly sampling an area using a separable kernel like I am. As I explore in a bit, perhaps they're using down/upsampling to reduce the number of pixels they operate over and to lower the sampling area. There's also this interesting patent of Apple's on multilevel sampling for a Gaussian blur, which might lead to a faster blur here.
Replicating the iOS 7 control panel blur
The reason why there is so much interest right now in performant Gaussian blurs is that they are a core component in iOS 7. Elements like the new control center blur the content behind them, some components doing so even while background elements are updated live (such as a camera view). However, Apple has only provided us limited access to these elements, so several people have taken to rolling their own blur implementations. Apple has also provided a UIImage category to help with this.
I wanted to take these new blurs and see if I could replicate Apple's blur effect with them. I started by looking at the control center view. Their blur in that case appears to be Gaussian, and it looks to use a sigma of around 48-50. That presents a problem, because a sigma of 48-50 means a sampling pixel sampling radius of at least 55 or so pixels. If you look at the above benchmarks, there's no way you're doing that on the full screen (an iPhone 5 screen size has slightly fewer pixels than 720p, 727,040 vs. 921,600) at even 30 FPS unless you're using an iPhone 5S.
This is where we can cut some corners, as I believe Apple is. Instead of filtering the image in its native resolution, I used OpenGL's native support for linear interpolation to downsample the source image by 4X in width and height, blurred that downsampled image, then linearly upsampled via OpenGL afterward. This both cuts the number of pixels to be operated on by 16X, and also reduces the needed blur sigma to 14. This makes the blur much more reasonable.
Apple also appears to reduce the dynamic range of luminance in the blurred image to enhance legibility of controls above it. I tried to match that as best I could with a shader that acts on the blurred content. This could use some slight tweaks, but the overall result (on the right) is very close to what Apple does with their blur (on the left):
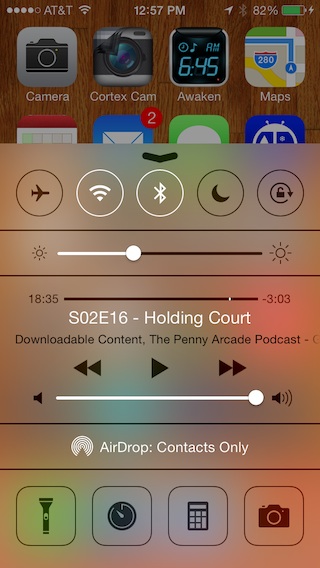
As far as performance goes, here's the frame times in milliseconds for 720p video run through this, along with the FPS this provides:
| Device | 720p Frame Processing Time (ms) | FPS Equivalent |
| iPhone 4 | 104 | 10 |
| iPhone 4S | 31 | 32 |
| iPad 3 | 32 | 31 |
| iPhone 5 | 16 | 62 |
| iPhone 5S | 5 | 200 |
Now, this is about the worst case under which you'd use a blur like this (Retina iPads excluded). Odds are, you're going to be blurring a much smaller region of the screen, or if you're going to deal with a camera feed you'll be looking at a lower resolution preview than 720p. Still, any device newer than the iPhone 4 can hit 30 FPS when processing a full 720p video stream through this, and if you run my FilterShowcase example from GPUImage you can see this working on a live camera feed:

It's worth exploring whether further downsampling can be done without too much image degradation. Apple also does an interesting three-pass box blur to approximate a Gaussian in their UIImage blur category, but I didn't find that to be as fast as my straight Gaussian under the same conditions. Still, there might be a way to make that faster.
Potential areas for improvement
As you can see in my benchmarks against Core Image, there's still plenty of room for improvement. More interesting techniques, like multilevel sampling (as I referenced earlier with that Apple patent, for example), or the use of summed area tables, could be employed to reduce the computational demands of large-radii blurs. As I said above, I'm really curious about how Core Image achieves its near constant-time blurring over multiple large blur radii.
Also, there appears to be a little color fringing appearing at very high blur radii on certain devices (the iPhone 4 in particular) that may be due to my use of lowp precision color math instead of mediump or highp precision. That's worth investigating, although there might be performance consequences in the use of higher precisions.